This procedure will walk you through the process of reimaging the DX OS Disk and installing a new LogRhythm-prepped instance of Rocky 9.
This process is a full wipe of the Operating System while retaining the mount point where Elasticsearch data is stored. This will delete system logs and all other CentOS 7/RHEL 7-specific configurations or files. Please backup any such files that you require, and/or ensure you have Rocky Linux 9/RHEL 9 installation packages for any utilities/agents you require to run on your systems.
Do not use the LogRhythm New-Install Rocky 9 ISO to perform upgrades to existing DX nodes. The New-Install ISO for Rocky 9 ISO runs a kickstart that will wipe data on all disks. In a multi-node cluster, the data can be recovered with replica shards, but in single-node cluster, the only way to restore data is SecondLook.
If you have more than one Data Indexer node, it is recommended to upgrade one node at a time and ensure the cluster returns to a green status following the upgrade before proceeding to the next node. This guards against data loss as well as reducing downtime.
Before You Begin
Verify the disk configuration on your Data Indexer (DX) is compatible with this upgrade method. Only DXs built with two or more disks will be able to proceed with this upgrade without data loss. If your DX was built with one disk do not proceed. Elasticsearch should be configured with the default data directory. For DXs with multiple data directories configured, contact LogRhythm Support or Professional Services for instructions.
-
The Rocky Linux 9/RHEL9 Setup wizard is requires the following input:
-
Root password: A password for the default root account and preferences for it.
-
Network configuration: IP address/netmask/gateway, DNS Servers, and NTP Servers.
-
-
Record the DX Cluster Name.
-
Backup the plan.yml and hosts file for your cluster off-box. You only need one copy of these files for each cluster you are working with, and they will be identical for all nodes within the same cluster.
-
Plan your upgrade order if you are upgrading a multi-node cluster. OS upgrades should be done in a specific order, and you should NOT start with the node from which the DX installer was most previously run.
If you have a multi-node cluster and are stepping through OS upgrades, you will have to re-run the DX installer after each node has been upgraded (i.e., a five-node DX cluster will require the DX installer to be run five times, once for each node, as you step through upgrading the OS one-by-one). To preserve the DX Cluster ID in a multi-node cluster, it is recommended you run the installer from a node that is actively participating in the cluster, not the node that was recently reimaged. For example, if you have a five-node cluster and you normally run the DX installer from DX1, you should execute the migration in the following order:
OS Upgrade DX2, run DX Installer from DX1
OS Upgrade DX3, run DX Installer from DX1
OS Upgrade DX4, run DX Installer from DX1
OS Upgrade DX5, run DX Installer from DX1
OS Upgrade DX1, run DX Installer from DX2
-
Review your disk configuration. It should look similar to this, where the mountpoint for /usr/local/logrhythm is on a dedicated disk (sda in this example):
[logrhythm@dx ~]$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 39.3T 0 disk └─sda1 8:1 0 39.3T 0 part └─vg_data-lv_usrlocallogrhythm 253:7 0 39.3T 0 lvm /usr/local/logrhythm sdb 8:16 0 223.5G 0 disk ├─sdb1 8:17 0 500M 0 part /boot/efi ├─sdb2 8:18 0 1G 0 part /boot └─sdb3 8:19 0 222G 0 part ├─vgroup1-root 253:0 0 99.5G 0 lvm / ├─vgroup1-vswap 253:1 0 4G 0 lvm [SWAP] ├─vgroup1-audit 253:2 0 21.6G 0 lvm /var/log/audit ├─vgroup1-varlog 253:3 0 21.6G 0 lvm /var/log ├─vgroup1-var 253:4 0 21.6G 0 lvm /var ├─vgroup1-home 253:5 0 43.1G 0 lvm /home └─vgroup1-temp 253:6 0 10.8G 0 lvm /tmp sr0 11:0 1 1.7G 0 rom
-
Record the output of /etc/fstab into a temporary notepad file. This will be required to remount your Elasticsearch Data Disk after the OS upgrade is complete.
[logrhythm@dx ~]$ cat /etc/fstab
-
Verify your Elasticsearch Data Path is under the correct mountpoint by launching LogRhythm Configuration Manager on your Platform Manager or XM:
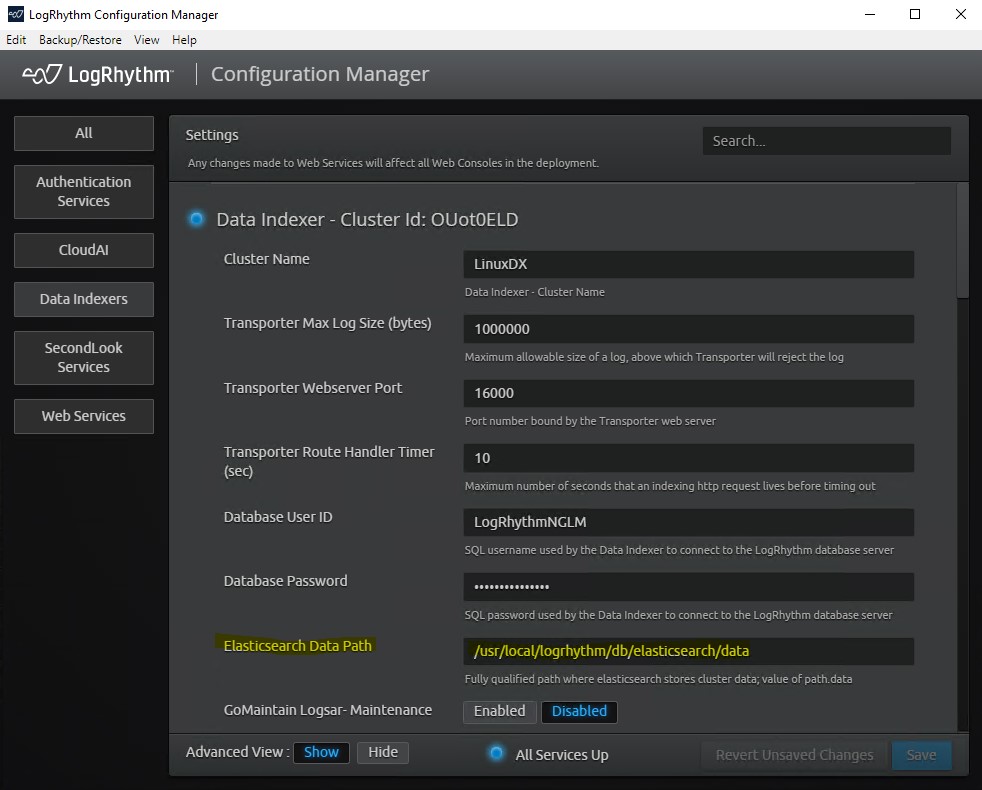
System Requirements
LogRhythm SIEM version 7.13.0 introduced support for Rocky Linux 9 and RHEL 9. Upgrading to SIEM version 7.13.0 or later is required before upgrading to Rocky Linux 9/RHEL9.
The LogRhythm Upgrade ISO can be used with any DX Installer version matching the SIEM version 7.13.0 or higher. Replace the LRDataIndexer-13.###.0.0.x86_64.run file in the /home/logrhythm/Soft directory with the LRDataIndexer which matches your SIEM version.
RHEL Licensing
LogRhythm customers are not entitled to Red Hat Enterprise Linux (RHEL) licensing, nor does LogRhythm have the ability to sell/procure this licensing. The use of RHEL is entirely optional and not required for LogRhythm to function. However, some customers prefer to use non-open-source operating systems that LogRhythm supports due to the compatibility between Rocky Linux 9 and RHEL. LogRhythm does not provide support of the RHEL Operating System itself or assist with upgrades.
Upgrade Instructions
To upgrade CentOS7/RHEL 7 to Rocky Linux 9 using the LogRhythm Upgrade ISO, do the following:
-
If upgrading a multi-node cluster, increase the Node Left timeout to 2hrs or more to allow plenty of time for each node to be upgraded without starting shard recovery:
curl -X PUT "localhost:9200/_all/_settings?pretty" -H 'Content-Type: application/json' -d' { "settings": { "index.unassigned.node_left.delayed_timeout": "2h" }}'
-
Insert the Installation DVD or mount the installation ISO via a Lights Out Management platform, such as Dell iDRAC.
-
Shut down the Data Indexer from command line, then boot the server using the mounted Installation Media.
This will launch Kickstart, which will handle OS Installation, Disk Configuration, Package Installation and prepping the system for LogRhythm software.sudo shutdown now
-
Once the machine has successfully rebooted, login with the logrhythm user using default credentials.
-
Press y to run the setup script.
-
You will be prompted for network and NTP details.
At each prompt, detected or default values are displayed in parentheses. To accept these values, press Enter. -
Enter the network and NTP information, as follows:
Prompt
Description
IP Address
The IP address that you want to assign to this Data Indexer node.
Netmask
The netmask to use.
Default gateway
The IP address of the network gateway.
NTP servers
The IP address of one or more NTP servers. Enter the IP address of each server one at a time, followed by Enter. When you are finished, press Ctrl + D to end.
After completing the items in the configuration script, the system will test connectivity to the default gateway and the NTP servers. If any of the tests fail, press n when prompted to enter addresses again.
If you plan to deploy the Indexer in a different network environment and you expect the connectivity tests to fail, you can press y to proceed.
-
-
You will need to mount the storage on the Data volume to retain your Elasticsearch Data. Before you started the upgrade process, you should have recorded the fstab output, as described in the Before You Begin section above.
You will need to remount the /usr/local/logrhythm path:sudo mkdir -p /usr/local/logrhythm sudo su -c "echo '/dev/mapper/vg_data-lv_usrlocallogrhythm /usr/local/logrhythm ext4 nofail 1 2' >> /etc/fstab" sudo mount /usr/local/logrhythm sudo systemctl daemon-reload
The /etc/fstab entry may vary from environment to environment depending on how your DX storage was configured. The above commands assume your DX was built using the LogRhythm ISO, or is a LogRhythm factory appliance, which creates a volume group called "vg_data-lv_usrlocallogrhythm" by default. If your Data Indexer was built in a public cloud environment, on your own hardware, or in a virtual environment, the /etc/fstab configuration may need to be adjusted to mount the data volume correctly. Please consult with LogRhythm Support or Professional Services if you are unsure.
-
Verify your Disk Partition Layout is correct.
The /usr/local/logrhythm mountpoint should be listed:[root@localhost logrhythm]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sda 8:0 0 39.3T 0 disk └─sda1 8:1 0 39.3T 0 part └─vg_data-lv_usrlocallogrhythm 253:2 0 39.3T 0 lvm /usr/local/logrhythm sdb 8:16 0 223.5G 0 disk ├─sdb1 8:17 0 500M 0 part /boot/efi ├─sdb2 8:18 0 1G 0 part /boot └─sdb3 8:19 0 222G 0 part ├─vgroup1-root 253:0 0 99.5G 0 lvm / ├─vgroup1-vswap 253:1 0 4G 0 lvm ├─vgroup1-audit 253:3 0 21.6G 0 lvm /var/log/audit ├─vgroup1-varlog 253:4 0 21.6G 0 lvm /var/log ├─vgroup1-var 253:5 0 21.6G 0 lvm /var ├─vgroup1-home 253:6 0 43.1G 0 lvm /home └─vgroup1-temp 253:7 0 10.8G 0 lvm /tmp sdc 8:32 1 0B 0 disk sr0 11:0 1 1024M 0 romAnd the partition should now be mounted to /usr/local/logrhythm:
[logrhythm@dxlog-14117 Soft]$ df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 4.0M 0 4.0M 0% /dev tmpfs 126G 0 126G 0% /dev/shm tmpfs 51G 27M 51G 1% /run /dev/mapper/vgroup1-root 98G 1.1G 92G 2% / /dev/sdb2 974M 177M 730M 20% /boot /dev/sdb1 500M 7.1M 493M 2% /boot/efi /dev/mapper/vgroup1-temp 11G 132K 10G 1% /tmp /dev/mapper/vgroup1-home 43G 1.8G 39G 5% /home /dev/mapper/vgroup1-var 22G 99M 20G 1% /var /dev/mapper/vgroup1-varlog 22G 21M 20G 1% /var/log /dev/mapper/vgroup1-audit 22G 520K 20G 1% /var/log/audit tmpfs 26G 0 26G 0% /run/user/1000 /dev/mapper/vg_data-lv_usrlocallogrhythm 40T 4.1G 38T 1% /usr/local/logrhythm
-
Copy the plan.yml file and the hosts file into /home/logrhythm/Soft.
These should be identical to the ones prior to the upgrade and match on all hosts in the cluster. If you are stepping through upgrading a multi-node cluster, you will want these files present on every node (see below). -
Run the PreInstall script to distribute the newly updated SSH keys from the host which you plan to run the installer from.
In a multi-node cluster you may need to clear the cached SSH keys from the host you run the installer from for the host you just upgraded the OS for. For example, in a three-node cluster:
-
OS Upgrade to DX02, run DX Installer from DX01 - You will need to clear the SSH keys for DX02 from DX01 at /home/logrhythm/.ssh/known_hosts or using ssh-keygen -R <IP_OF_DX02>
-
OS Upgrade to DX03, run DX Installer from DX01 - You will need to clear the SSH keys for DX03 from DX01 at /home/logrhythm/.ssh/known_hosts or using ssh-keygen -R <IP_OF_DX03>
-
OS Upgrade to DX01, run DX Installer from DX02 - You will need to clear the SSH keys for DX01 from DX02 at /home/logrhythm/.ssh/known_hosts or using ssh-keygen -R <IP_OF_DX01>
Elasticsearch Health Check errors may appear; however, this is expected and they can be ignored.
PreInstall.sh can be executed again to verify the keys.
[logrhythm@localhost Soft]$ sh ./PreInstall.sh Running PreInstall.sh as logrhythm user. Configuring Public Key Authentication. Checking if sshpass is installed (Required before running the Data Indexer install/upgrade). - sshpass is already installed. sshpass install check: OK Checking for existing keys for logrhythm user. Using existing keys. To generate new keys: remove the id_ecdsa and id_ecdsa.pub files from /home/logrhythm/.ssh/ and run the PreInstall script again. Enter logrhythm user password to copy keys to all nodes. SSH Password: Default: /home/logrhythm/Soft/hosts Plese enter the full path to the hosts file: Upgrade Detected. Error querying Consul agent: Get "http://127.0.0.1:8500/v1/kv/services/lr-dx-config/OUot0ELD/configs/DX_ES_PATH_DATA": dial tcp 127.0.0.1:8500: connect: connection refused Error querying Consul agent: Get "http://127.0.0.1:8500/v1/kv/services/lr-dx-config/OUot0ELD/configs/DX_ES_PATH_DATA": dial tcp 127.0.0.1:8500: connect: connection refused Elasticsearch data path is set in consul, using the consul value. ClusterID: OUot0ELD Cluster Name: LinuxDX Data Path: Using /home/logrhythm/Soft/hosts file to copy keys. ****Reading hosts file**** Setting SSH passwordless login for host 10.7.10.139 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/logrhythm/.ssh/id_ecdsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: WARNING: All keys were skipped because they already exist on the remote system. (if you think this is a mistake, you may want to use -f option) Keys copied successfully to host 10.7.10.139. **************************** Verifying permissions on hosts for Pulic Key Authentication on DX Setting permssions on /home/logrhythm directory to 700. Checking for cluster name in data path. Checking for directory /LinuxDX ClusterName in data path check: OK Host configuration updated on DX Checking cluster health. Elasticsearch cluster health must be green before proceeding with upgrade. The Elasticsearch cluster health MUST be green before performing the upgrade. - Please verify the elasticsearch service is started on all nodes before proceeding. - Verify the cluster health is 'green' using: curl localhost:9200/_cluster/health?pretty - If still having issues, please review the /var/log/elasticsearch/<clustername>.log for more information. ************************************************************** Testing ssh as logrhythm user using Public Key Authentication. -- DX: SSH OK PreInstall complete. Please review output for any errors. These errors should be corrected before executing Data Indexer installer.
-
-
Run the Data Indexer Installer with the --force and --es-cluster-name options to reinstall the services and restore OS specific configurations.
If you have a multi-node cluster, it is recommended you re-run the Data Indexer Installer from the same node you originally installed it.Ensure the DX Cluster Name matches your cluster name from prior to the OS upgrade. Changing the DX Cluster Name could result in data loss.
This will start the remaining DX services when the install is finished, and your data should be accessible.
sudo sh ./LRDataIndexer-13.59.0.0.x86_64.run --hosts /home/logrhythm/Soft/hosts --plan /home/logrhythm/Soft/plan.yml --es-cluster-name LinuxDX --force
If you have a multi-node cluster and are stepping through OS upgrades, you will have to re-run the DX installer after each node has been upgraded (i.e., a five-node DX cluster will require the DX installer to be run five times, once for each node, as you step through upgrading the OS one-by-one). To preserve the DX Cluster ID in a multi-node cluster, it is recommended you run the installer from a node that is actively participating in the cluster, not the node that was recently reimaged. For example, if you have a five-node cluster and you normally run the DX installer from DX1, you should execute the migration in the following order:
OS Upgrade DX2, run DX Installer from DX1
OS Upgrade DX3, run DX Installer from DX1
OS Upgrade DX4, run DX Installer from DX1
OS Upgrade DX5, run DX Installer from DX1
OS Upgrade DX1, run DX Installer from DX2
-
Run the following commands to update service ownership to the following directories in order for the LogRhythm Common services to function:
sudo chown -R LogRhythmAPIGateway.LogRhythmAPIGateway /usr/local/logrhythm/LogRhythmAPIGateway sudo chown -R LogRhythmMetricsCollection.LogRhythmMetricsCollection /usr/local/logrhythm/LogRhythmMetricsCollection sudo chown -R LogRhythmServiceRegistry.LogRhythmServiceRegistry /usr/local/logrhythm/LogRhythmServiceRegistry sudo systemctl restart LogRhythmAPIGateway LogRhythmMetricsCollection LogRhythmServiceRegistry
After this step, it may take 3-5 minutes for Elasticsearch to start on its own. There is no need to manually restart it.
-
For DX7500 models which have two Elasticsearch processes installed, you need to restore permissions to the secondary data directory after the DX installer is run and also re-run the Nodes Installer to re-install the second Elasticsearch instance:
[logrhythm@localhost elasticsearch]$ sudo chown -R elasticsearch:elasticsearch /usr/local/logrhythm/elasticsearch-data [logrhythm@localhost elasticsearch]$ sudo sh ./LRDXNodeInstaller-13.64.0.1.x86_64.run --hosts /home/logrhythm/Soft/hosts --add
-
Check the Cluster Health status.
It should be "Green."Multi-node clusters or clusters with many indexes may take some time to transition from Red to Yellow to Green.
Monitor the "active_shards_percent_as_number".
[logrhythm@localhost elasticsearch]$ curl localhost:9200/_cluster/health?pretty { "cluster_name" : "LinuxDX", "status" : "green", "timed_out" : false, "number_of_nodes" : 1, "number_of_data_nodes" : 1, "active_primary_shards" : 18, "active_shards" : 18, "relocating_shards" : 0, "initializing_shards" : 0, "unassigned_shards" : 0, "delayed_unassigned_shards" : 0, "number_of_pending_tasks" : 0, "number_of_in_flight_fetch" : 0, "task_max_waiting_in_queue_millis" : 0, "active_shards_percent_as_number" : 100.0
-
Check your indexes to validate that historical indexes from prior to the upgrade are present.
In the example below, the output has only one day of indexes; however, typically many days should be present.
[logrhythm@localhost elasticsearch]$ curl localhost:9200/_cat/indices/logs-* green open logs-2023-10-23 nRhq6zUXStCK1RUSrmU8kg 2 0 6384661 2563 2gb 2gb
-
Return the Node Left timeout setting to the default using the following command:
curl -X PUT "localhost:9200/_all/_settings?pretty" -H 'Content-Type: application/json' -d' { "settings": { "index.unassigned.node_left.delayed_timeout": "60m" }}
-
Validate all spooling has cleared from the "DXReliablePersist" folder in the Data Processor State directory before proceeding to upgrade any further nodes.
-
Reinstall the LogRhythm Agent if it was previously installed and configured using the instructions outlined at Install a System Monitor on UNIX/Linux.