This guide describes how to install and configure the LogRhythm Disaster Recovery (DR) solution, which protects businesses from potential site failures due to catastrophic events (power outage, fire, flood, etc.). If a failure occurs, the DR solution helps businesses quickly recover the key LogRhythm SIEM databases and continue log-collection activities.
Intended Audience
This guide is intended for LogRhythm Professional Services to install and configure the DR solution for customers. LogRhythm customers can also read this document to learn about the DR solution.
LogRhythm’s Disaster Recovery (DR) solution includes SIEM software running in two LogRhythm deployments: one on a Primary site and the other on a Secondary site. The Primary site includes the active Platform Manager, which sends replicated data to the Secondary Platform Manager. The Secondary site essentially becomes a “hot standby” in a planned outage, natural disaster, or attack.
Appliance Configurations
The Primary site can include one Platform Manager, one or more Data Processors, one or more Data Indexers, optional AI Engines (on-site or remote), and multiple remote Agents that actively monitor systems and collect logs. To create a standby solution, you can configure the Secondary site in several ways. At a minimum, you use the DR solution to replicate the Platform Manager database (EMDB), which contains key LogRhythm data and configuration information. Depending on business needs, you can also replicate the Events, Alarms, LogMart, and CMDB databases.
LogRhythm Archives are not included in the DR solution’s replication, since Archive files are part of the individual Data Processors, not the Platform Manager. To protect LogRhythm Archives, administrators must manually back up the Archive files from the Data Processors to another system or configure them for replication in a Storage Area Network (SAN).
Example 1: EMDB Replication Only
This example shows a scenario where only the Platform Manager database (EMDB) is replicated on the Secondary site.
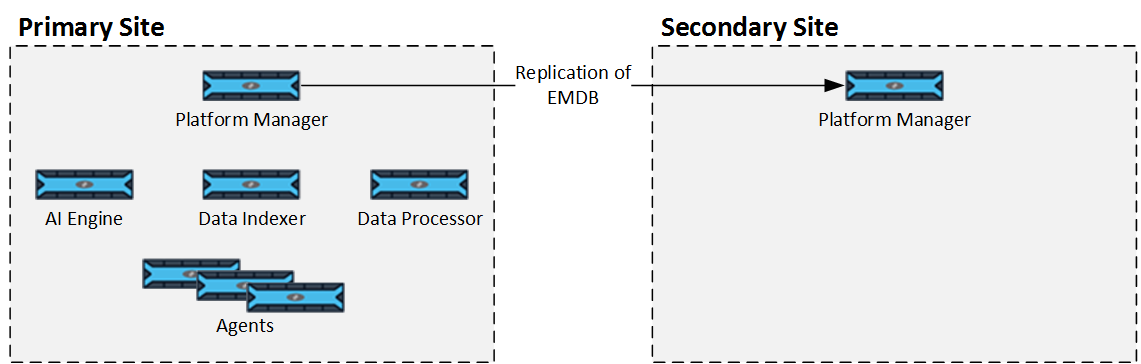
In a failover scenario, Agents installed on the Platform Manager may not be accessible, and therefore should not be used as primary collection points.
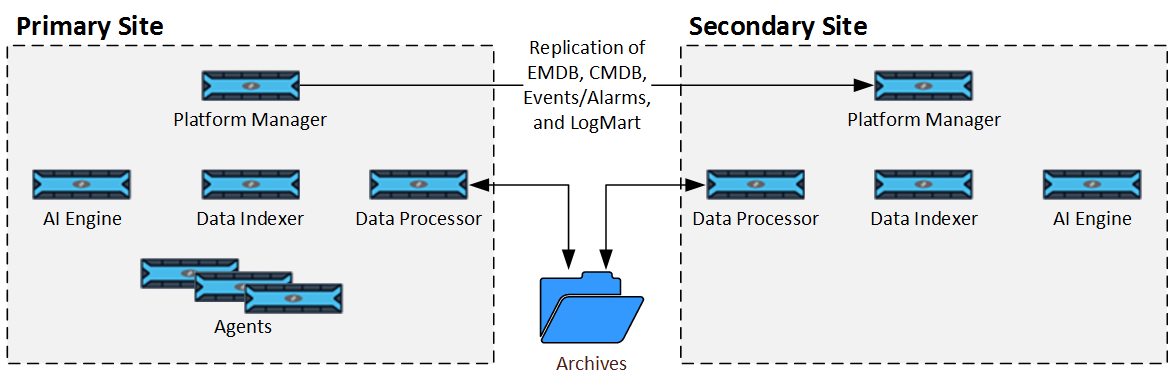
Example 2: Full Protection with Minimal Disruption
This example shows a scenario where the DR solution replicates all LogRhythm databases to the Secondary site. This Secondary site also includes a standby Data Processor, Data Indexer, and AI Engine, in case the key SIEM components on the Primary site are unavailable for a long period of time. In addition, the Archives are manually backed up to another system or replicated in a SAN. Archives are available to Data Processors in the Primary site and the Secondary site
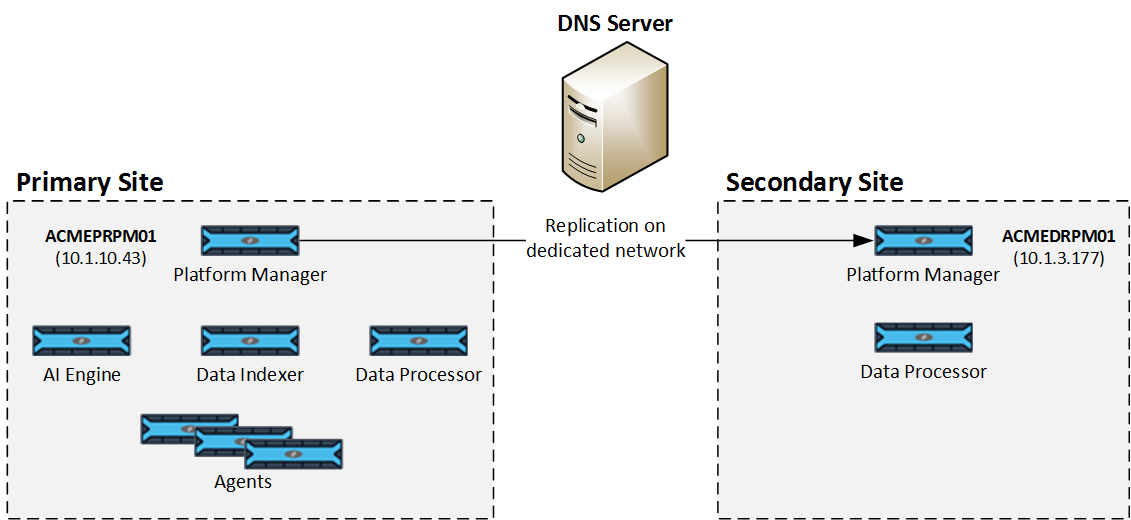
DNS Infrastructure
All components within the Primary and Secondary sites must include a common DNS infrastructure. When configuring the DNS infrastructure, follow these guidelines:
-
Platform Managers. A common DNS record can point to either the IP address of the Primary Platform Manager or the IP address of the Secondary Platform Manager.
If leveraging automatic DNS record switching, created at time of setup, a record named LogRhythmDR will be created. To enable this functionality, the DNS zone hosting the LogRhythmDR record must be configured to allow secure updates from clients. Note that this record can be manually updated on failover if these requirements cannot be met. Additionally, in order for automatic updates to the Cluster DNS record to function the network interface hosting the Failover Cluster IP must have the “Register this connection’s address in DNS” feature enabled.
-
Data Processors, Data Indexers, the LogRhythm Configuration Manager, and AI Engines. These systems point to the Platform Manager using a DNS name rather than an IP address. Remote components should also support DNS for connecting to either a Primary or Secondary site.
-
Agents. The Agents can use DNS to identify new Mediator host connections. The Agent resolves the DNS name to IP upon every new connection attempt. You can also configure Agents to use a different Data Processor (Data Processor to Use setting, under the Data Processor Settings tab of the Agent Properties dialog box) in Deployment Manager.
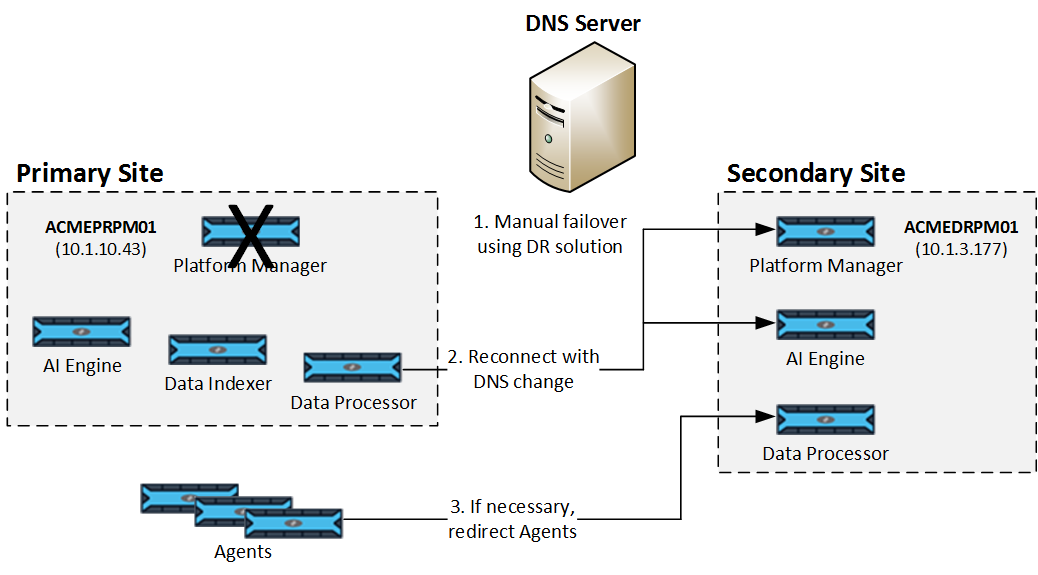
Overview of the Failover Process
The failover process depends on whether the Primary site was purposely shut down (Planned Failover) or the Primary site went down unexpectedly (Unplanned Failover). In either case, you must manually perform a failover, as outlined below:
-
Manually initiate the failover, using the appropriate process:
-
Planned Failover. Go to the Primary (active) site and use the DR Control (DR_Monitoring.ps1) script to initiate the failover to the standby site.
-
Unplanned Failover. Go to the Secondary (standby) site and use the DR Control (DR_Monitoring.ps1) script to initiate the failover to the standby site.
-
-
Update the common DNS record so the Primary site components point to the IP address of the Secondary Platform Manager. Once the time to live (TTL) limit is reached, all systems within the Primary site reconnect to the newly activated Platform Manager.
If leveraging automatic DNS record switching, created at time of setup, this step will be done automatically.
-
If a Data Indexer is unavailable on the Primary site, reconnect Data Processors to a new Data Indexer by changing the DNS records or using the Deployment Manager in the Client Console.
Contents
The following pages are contained within this guide: