Pipeline augmentation allows you to add custom parsing to existing LogRhythm (LR) pipelines, and allows you to parse any field in the raw log, and have it show up in the SIEM as a LogRhythm metadata field.
Since you are adding onto existing LR system pipelines, your augmented pipeline will still receive parsing improvements and bug fixes when released.
Pipeline Augmentation is a custom extension of existing LogRhythm system pipelines. If you want to create your own custom pipeline, see
Create Custom Open Collector Pipelines.
Workflow
Logs ingested by the Open Collector go through a sequence of transformative processes before being sent to the Agent. These processes include the Transforms and Syslog Conversion subcomponents that make up the parsing topology. The augmentation option provides an additional subcomponent that allows you to add custom parsing for a pipeline that LogRhythm supports (for a visual representation of the Parsing Topology, see the diagram below).
As with Custom Pipeline Creation, we use JQ for parsing alterations to our JSON logs.
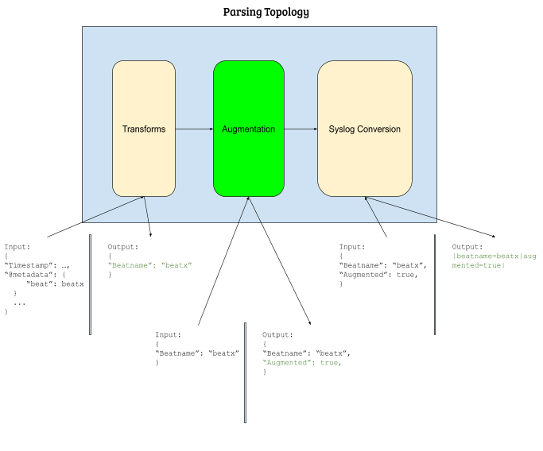
Augmenting a Pipeline
Prerequisites:
-
Open Collector version 5.1.1 or greater.
-
The ocpipeline tool, version 5.1.0 or greater.
-
The lrjq utility, version 5.1.0 or greater.
-
The lrctl image, version 5.1.1 or greater.
-
A raw beat log that you want to augment.
The following procedure describes how to augment a pipeline, using EventHubBeat as an example. The custom parsing in this example will map the host name of the heart beat log to sname and convert seconds to minutes. Below is an example of an eventhubbeat heart beat log.
{
"@timestamp":"2020-01-13T07:44:02.505Z", "@metadata":{ "beat":"eventhubbeat", "type":"doc", "version":"6.6.0" }, "heartbeat":"{\"service_name\":\"eventhubbeat\",\"service_version\":\"6.6.0\",\"time\":{\"seconds\":1578901442505540100},\"status\":{\"code\":2,\"description\":\"Service is Running\"}}",
"beat":{ "version":"6.6.0", "name":"f1a0791c9459", "hostname":"f1a0791c9459" }, "host":{ "name":"f1a0791c9459" }}
Step 1: Visualize Your Augmentation
LogRhythm provides a testing utility so you can see the output of Transforms from the Parsing Topology (see the Parsing Topology diagram above). This testing utility shows you exactly what happens to your raw beat log during the Transforms phase.
-
Save your log to a JSON file, for example heartbeat.json.
cat heartbeat.json | ./lrctl oc pipe test transformAfter running the command, you will see a message like this:
The supplied input file matches pipeline: beat_heartbeat_pipe
{ "beatname": "eventhubbeat", "device_type": "heartbeat", "normal_msg_date": 1578901442505000000, "original_message": "{\"@metadata\":{\"beat\":\"eventhubbeat\",\"type\":\"doc\",\"version\":\"6.6.0\"},\"@timestamp\":\"2020-01-13T07:44:02.505Z\",\"beat\":{\"hostname\":\"f1a0791c9459\",\"name\":\"f1a0791c9459\",\"version\":\"6.6.0\"},\"heartbeat\":\"{\\\"service_name\\\":\\\"eventhubbeat\\\",\\\"service_version\\\":\\\"6.6.0\\\",\\\"time\\\":{\\\"seconds\\\":1578901442505540100},\\\"status\\\":{\\\"code\\\":2,\\\"description\\\":\\\"Service is Running\\\"}}\",\"host\":{\"name\":\"f1a0791c9459\"}}", "reason": "Service is Running", "result": 2, "seconds": 1578901442505540000, "tag1": "Service is Running", "version": "6.6.0" }
When you write your pipeline augmentation, the entire JSON log output in JQ above will correspond to your .output.
Your raw beat log (original_message field above) will correspond to your .input.
Step 2: Export the LR Pipeline from the Open Collector
Select the LR pipeline you want to augment, and export it from the Open Collector.
-
View the list of available pipelines on your Open Collector:
./lrctl oc -- pipe statusYou will see a list that looks something like this:
Pipeline Name Enabled
logrhythm/cisco_amp/cisco_amp_pipe yes
logrhythm/gmail_message_tracking/gmail_message_tracking_pipe yes
logrhythm/sophos_central/sophos_central_pipe yes
logrhythm/pubsub/pubsub_pipe yes
logrhythm/s3/s3_pipe yes
logrhythm/eventhub/eventhub_pipe yes
logrhythm/gsuite/gsuite_pipe yes
logrhythm/metricbeat/metricbeat_pipe yes
logrhythm/heartbeat/heartbeat_pipe yes
logrhythm/beat_heartbeat/beat_heartbeat_pipe yes
logrhythm/generic/generic_pipe yes
-
Select the pipeline you want to augment and export it. For example, to export the logrhythm/beat_heartbeat/beat_heartbeat_pipe pipeline, run the following command:
./lrctl oc pipe augment export --name logrhythm/beat_heartbeat/beat_heartbeat_pipe --outfile beat_heartbeat.pipeYou should see a file called beat_heartbeat.pipe.
Step 3: Install and Unpack the ocpipeline Script
-
Install the ocpipeline script:
./lrctl ocpipeline install
-
Unpack the .pipe file to an empty directory:
./ocpipeline unpack --source beat_heartbeat.pipe beat --destination beat_heartbeatThe beat_heartbeat destination directory is automatically generated. You will see the following files in the beat_heartbeat destination directory:
-
-
augment.jq
This is where you can write your custom augment logic. Add, delete, or update log fields.
-
-
-
augmentation.root
Metadata file that defines the pipeline that you're augmenting. Do not modify this file.
-
-
-
entry.jq
The entry point for JQ augmentation. This is the root file or main function where the Open Collector will run from.Do not modify this file.
-
-
-
lib.jq
Library functions provided for you to use.
-
Step 4: Modify augment.jq
Navigate to your destination directoryand modify augment.jq.
# augment your pipeline for additional transforms logic
def augment:
# write your code here
.output.sname =.input.host.name# maps the sname output to the original message's host name field
|
.input.heartbeat as $heartbeat# assigns the original message's heartbeat field as a variable called heartbeat
|
($heartbeat | fromjson) as $heartbeatJSON# decodes from string the heartbeat variable and assigns it to heartbeatJSON
|
.output.minutes = $heartbeatJSON.time.seconds / 60# maps the minutes output by dividing the seconds field by 60.
# you can also use conditional statement (if-then-else) to write your own custom logic
if
$heartbeatJSON.status.code == 1
then
.output.status = "Started"# maps the status output to Started if result code value is 1.
elif
$heartbeatJSON.status.code == 2
then
.output.status = "Running"# maps the status output to Running if result code value is 2.
elif
$heartbeatJSON.status.code == 3
then
.output.status = "Stopped"# maps the status output to Stopped if result code value is 3.
else
.output.status = "Unknown"# maps the status output to Unknown if result code value is not valid.
end
As noted in Step 1 above, .output corresponds to the entire JSON log outputted in the test command, and .input corresponds to the raw beat log (original_message field).
Dot(.) corresponds to a JSON field identity. So .input.host.name corresponds to:
{ "host": { "name": "xxx" }}
If you want to see the possible mappings for logs, see Create Custom JQ Pipeline Augmentations | MPE Rule Builder. For our objective, we're mapping the sname to the host name in the original message.
We're also mapping the minutes to the seconds field in the original message and converting the value by dividing it by 60.
Step 5: Test Your Augmented Changes
-
Install the lrjq utility:
./lrctl lrjq install
-
Save your log from the output of Step 1, for example transformed.json:
cat transformed.json | ./lrjq run -f beat_heartbeat/entry.jqAfter running the command, you will see a message like this:
{"augmented":true,"beatname":"eventhubbeat","device_type":"heartbeat","minutes":26315024041759000,"normal_msg_date":1578901442505000000,
"original_message":"{\"@metadata\":{\"beat\":\"eventhubbeat\",\"type\":\"doc\",\"version\":\"6.6.0\"},
\"@timestamp\":\"2020-01-13T07:44:02.505Z\",\"beat\":{\"hostname\":\"f1a0791c9459\",\"name\":\"f1a0791c9459\",\"version\":\"6.6.0\"},
\"heartbeat\":\"{\\\"service_name\\\":\\\"eventhubbeat\\\",\\\"service_version\\\":\\\"6.6.0\\\",\\\"time\\\":{\\\"seconds\\\":1578901442505540100},
\\\"status\\\":{\\\"code\\\":2,\\\"description\\\":\\\"Service is Running\\\"}}\",\"host\":{\"name\":\"f1a0791c9459\"}}",
"reason":"Service is Running","result":2,"seconds":1578901442505540000,"sname":"f1a0791c9459","tag1":"Service is Running","version":"6.6.0"}
Make sure you run lrjq against entry.jq (the main entry point) and not augment.jq (where you wrote your changes).
Fields are highlighted in bold to denote augmented changes.
Step 6: Package and Import the Augmented Pipeline
-
Package the augmented pipeline:
./ocpipeline package --source beat_heartbeat --destination . --force
If you have an existing beat_heartbeat.pipe file in your directory, the force flag is required to overwrite it.
After running the command, you will see the following message:
.pipe file generated at: /Users/logrhythm/xxx/beat_heartbeat.pipe
-
Import the augmented pipeline:
cat beat_heartbeat.pipe | ./lrctl oc pipe augment importAfter running the command, you will see the following message:
Expanding 5 filesSuccessfully imported augmented pipeline logrhythm/beat_heartbeat/beat_heartbeat_pipe
-
Restart the Open Collector:
./lrctl oc restart
Step 7: Test against the full Parsing Topology of the Open Collector
Make sure you are using the raw beat log for your test. Do not use the transformed log.
-
Test your augmented pipeline:
cat heartbeat.json | ./lrctl oc pipe test outputAfter running the command, you will see a message like this:
The supplied input file matches pipeline: beat_heartbeat_pipe
|beatname=eventhubbeat|device_type=heartbeat|result=2|version=6.6.0|reason=Service is Running|minutes=26315024041759000
|seconds=1578901442505540000|sname=f1a0791c9459|augmented=true|tag1=Service is Running
|original_message={\"@metadata\":{\"beat\":\"eventhubbeat\",\"type\":\"doc\",\"version\":\"6.6.0\"},
\"@timestamp\":\"2020-01-13T07:44:02.505Z\",\"beat\":{\"hostname\":\"f1a0791c9459\",\"name\":\"f1a0791c9459\",\"version\":\"6.6.0\"},
\"heartbeat\":\"{\\\"service_name\\\":\\\"eventhubbeat\\\",\\\"service_version\\\":\\\"6.6.0\\\",\\\"time\\\":{\\\"seconds\\\":1578901442505540100},
\\\"status\\\":{\\\"code\\\":2,\\\"description\\\":\\\"Service is Running\\\"}}\",\"host\":{\"name\":\"f1a0791c9459\"}}|
The log from this output is the same log output you will see coming into the Agent. The next time a log gets ingested by the Open Collector, it will go through the augmentation phase if it matches the target pipeline.
Removing Pipeline Augmentation
If you remove your augmentation, it is permanent. We do not store a backup copy of your augmentation.
-
To Remove your augmentation, run the following command for your pipeline:
./lrctl oc pipe augment remove --name logrhythm/beat_heartbeat/beat_heartbeat_pipeAfter running the command you will see the following message:
successfully deleted pipeline augmentation for logrhythm/beat_heartbeat/beat_heartbeat_pipe
-
Restart the Open Collector.
./lrctl oc restart
MPE Rule Builder
Below is a list of field mappings for the MPE. When you augment your logs, you should map each log field to one of these fields.
account, action, amount, augmented, beatname, command, cve, device_type, dinterface, dip,
dmac, dname, dnatip, dnatport, domainimpacted, domainorigin, dport, group, hash,
kilobytes, kilobytesin, kilobytesout, login, milliseconds, minutes, object, objectname,
objecttype, packetsin, packetsout, parentprocessid, parentprocessname, parentprocesspath,
process, processid, protname, protnum, policy, quantity, rate, reason, recipient,
responsecode, result, seconds, sender, serialnumber, session, sessiontype, severity,
sinterface, sip, size, smac, sname, snatip, snatport, sport, status, subject, tag1, threatid,
threatname, time, url, useragent, vendorinfo, version, vmid,
FAQ/Troubleshooting
I have multiple instances of different Beats. Can I augment multiple pipelines?
Yes.
I messed up my augmentation and accidentally imported it into the Open Collector.
Export your augmented pipelines, make the required modifications, and re-import into the Open Collector (Steps 2->6).
Make sure you restart the Open Collector so that those changes take effect.
I'm not seeing my augmented changes when testing against the Open Collector's full Parsing Topology.
Did you restart the Open Collector after importing your changes?
I'm not familiar with writing JQ.
Check out the JQ manual for additional information on how to write JQ.
For experimenting with writing JQ, you can use the JQ playground.
You can also head on over to our community page and ask any specific questions you may have about pipeline augmentation.
What is the difference between Custom Pipeline Creation and Pipeline Augmentation?
Custom Pipeline Creation is the process of creating a new pipeline for on-boarding a collection device (ElasticBeat) that LR does not currently support.
This usually means that you will have to onboard a custom Beat and set up the delivery mechanism to send logs to the Open Collector container, where it will go through your custom pipeline parsing.
Pipeline Augmentation is the process of adding custom parsing to an LR-supported pipeline (i.e. Eventhub).
As an example, if you have a firehose that streams all your logs to AWS S3 and we do not have parsing support for one of the log sources, you can use pipeline augmentation for logrhythm/s3/s3_pipe.
Can I use augmentation for my custom pipeline?
No, the purpose of augmentation is to add or overwrite parsing to an existing LR pipeline while still being able to receive parsing improvements.
If you have a custom pipeline, there's no need to augment it. Just modify the parsing directly on your pipeline.