Configure a Data Processor to Duplicate Data Indexer Logs
Starting with LogRhythm SIEM version 7.22, Data Processors (DPs) have the ability to send data to multiple Data Indexer (DX) clusters. This configuration sends two identical copies of every log to both clusters, providing cluster-level redundancy of DX data. This feature supports an output of up to two clusters per DP. To search both clusters, a minimum of two DPs are required in the deployment. Each cluster can be single- or multi-node, Windows or Linux.
This feature can be used to provide DX cluster redundancy, or to assist with cluster migrations.
Searching against both clusters (repositories) will produce duplicate results. If multiple clusters will remain in place for redundancy purposes, users should select only a single repository to search from to avoid duplicate results.
Requirements
In order to configure a DP to duplicate DX data:
When used for redundancy purposes, both DX clusters should have the same type and size.
When used for Cluster Migration strategy, the indexing rate should be limited to the smallest of the two clusters.
Duplicate Data Processor Configuration
To configure a Data Processor to duplicate Data Indexer data, in the Client Console:
On the main toolbar, click Deployment Manager.
Click the Data Processors tab.
Double-click the Data Processor you want to configure.
The Data Processor Properties window appears.
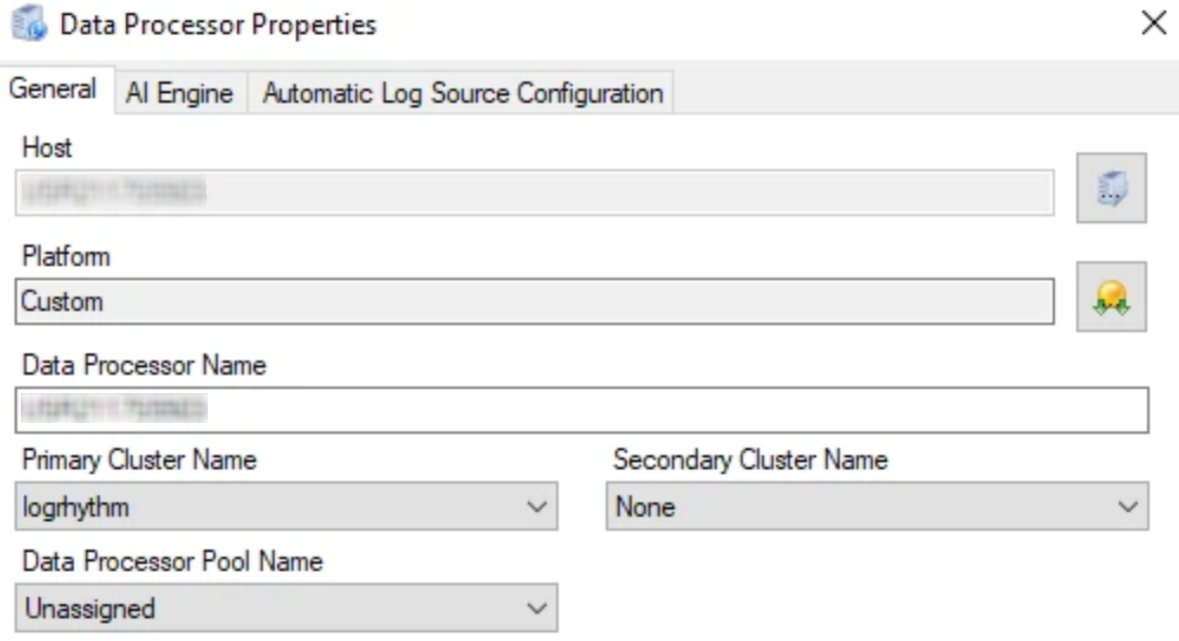
Open the Secondary Cluster Name drop-list and select the name of the cluster to which you would like logs to be duplicated.
When finished, click Apply, and then click OK.
The secondary cluster information is saved successfully.