Data Processor Pooling
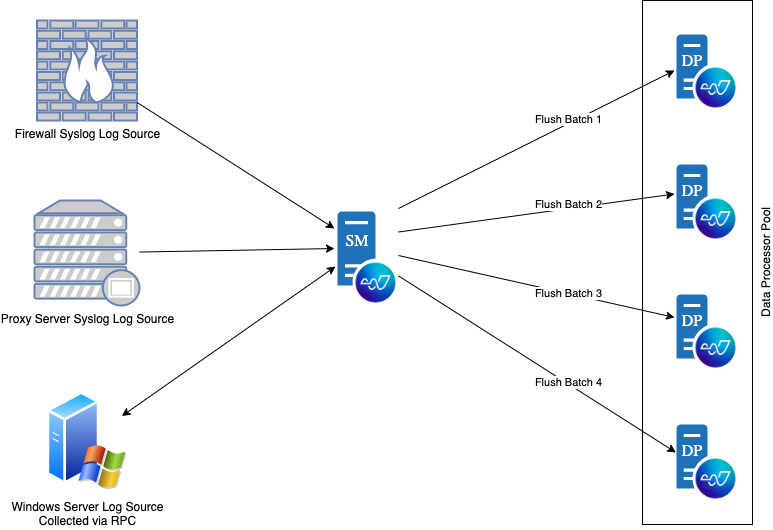
Data Processor pooling makes it easy for administrators to distribute log volume across a pool of Data Processors and create well-balanced Data Indexer clusters.
Administrators can quickly define Data Processor pools, assign Data Processors to those pools, and then configure agents to send logs to all Data Processors in the pool. Agents assigned to a DP pool use a round robin based log flushing mechanism to evenly distribute their logs across the Data Processors in the pool. One Data Processor in the pool is designated to receive heartbeats and message source states. If the control DP is unreachable or offline, the Agent will designate another Data Processor in the pool as the control DP.
Data Processor Pooling applies to all log sources and log types collected by an Agent.
Starting with version 7.13, Data Processor pooling is available to customers with multiple Data Processors in their deployment.
Data Processor Pooling mode is not enabled for deployments or agents on versions prior to 7.13. In such cases, Administrators can configure the Agent to pinned mode, which sends logs to a single Data Processor.