Open Collector Fields used in JQ parsing
The following tables list Open Collector fields used in JQ parsing.
Open Collector Special Fields
|
Field Name |
Description |
|---|---|
|
.output.beatname |
Field is required for Open Collector logs to work with the SIEM. |
|
.output.device_type |
Field used in log source type virtualization, this should be assigned. |
|
.output.fullyqualifiedbeatname |
Field used in log source type virtualization. Can divide log sources by FQBN in the SIEM. |
|
.output.normal_msg_date |
Field used for assigning a timestamp. If unassigned, current date/time is used. |
Open Collector LogRhythm Metadata Field List
|
.output.time
|
.output.rate
|
.output.dname
|
Flatten an Array for Parsing
If the json log message contains arrays that contain data that is needed for parsing, you must "fan" out the data into a new log message for each data element in the array.
The following example shows a json sample containing an array:
{
"@metadata": {
"beat": "filebeat",
"type": "doc",
"version": "6.6.0"
},
"@timestamp": "2020-12-31T13:40:42.142Z",
"host": {
"name": "eventhub37"
},
"response": {
"severity": 4,
"properties": {
"accessPolicies"
[
{
"subject": "Allow Secure Mobile Apps",
"result": "success"
},
{
"subject": "Block Insecure Mobile Apps",
"result": "notEnabled"
},
{
"subject": "Baseline policy: Require MFA for admins",
"result": "failed"
}
]
},
"category": "SignInLogs"
}
}
To flatten an array for parsing:
-
In custom log sources,
get_io_formatmust be run before any parsing is done. After you run that function, the reference to the array shown above is:.input.response.properties.accessPolicies -
To fan or flatten this array , you must create a log message for each array element. The code to accomplish this is included below and is based on the example json shown above. Paste this code into the transform or augment function of your custom JQ parsing, changing only the .input.response.properties.accessPolicies, and .input.response.properties fields to match your json array.
# get_io_format function only for custom pipeline, not needed for augment pipelines get_io_format | .input.response.properties.accessPolicies as $array | if ($array | type) == "array" then # Fan out the logs .single_log = flatten_array($array) | # Save flattened log back to original location in json structure .input.response.properties = ({ "accessPolicies" : [ .single_log ] }) else . end |
-
After the array is flattened any fields can be parsed from the array.
For example:add_field(.input."@metadata".beat; .output.beatname) | add_field(.input.response.properties.accessPolicies[0].subject; .output.subject)| add_field(.input.response.properties.accessPolicies[0].result; .output.result)| add_field(.input.response.category; .output.category)| add_field(.input.response.severity; .output.severity)|
-
The following is output from the parsing example shown above:
} "beatname": "filebeat", "category": "SignInLogs", "original_message": "{\"@metadata\":{\"beat\":\"filebeat\",\"type\":\"doc\",\"version\":\"6.6.0\"},\"@timestamp\":\"2020-12-31T13:40:42.142Z\",\"host\":{\"name\":\"eventhub37\"},\"response\":{\"category\":\"SignInLogs\",\"properties\":{\"accessPolicies\":[{\"result\":\"success\",\"subject\":\"Allow Secure Mobile Apps\"},{\"result\":\"notEnabled\",\"subject\":\"Block Insecure Mobile Apps\"},{\"result\":\"failed\",\"subject\":\"Baseline policy: Require MFA for admins\"}]},\"severity\":4}}", "result": "success", "severity": 4, "subject": "Allow Secure Mobile Apps" } { "beatname": "filebeat", "category": "SignInLogs", "original_message": "{\"@metadata\":{\"beat\":\"filebeat\",\"type\":\"doc\",\"version\":\"6.6.0\"},\"@timestamp\":\"2020-12-31T13:40:42.142Z\",\"host\":{\"name\":\"eventhub37\"},\"response\":{\"category\":\"SignInLogs\",\"properties\":{\"accessPolicies\":[{\"result\":\"success\",\"subject\":\"Allow Secure Mobile Apps\"},{\"result\":\"notEnabled\",\"subject\":\"Block Insecure Mobile Apps\"},{\"result\":\"failed\",\"subject\":\"Baseline policy: Require MFA for admins\"}]},\"severity\":4}}", "result": "notEnabled", "severity": 4, "subject": "Block Insecure Mobile Apps" } { "beatname": "filebeat", "category": "SignInLogs", "original_message": "{\"@metadata\":{\"beat\":\"filebeat\",\"type\":\"doc\",\"version\":\"6.6.0\"},\"@timestamp\":\"2020-12-31T13:40:42.142Z\",\"host\":{\"name\":\"eventhub37\"},\"response\":{\"category\":\"SignInLogs\",\"properties\":{\"accessPolicies\":[{\"result\":\"success\",\"subject\":\"Allow Secure Mobile Apps\"},{\"result\":\"notEnabled\",\"subject\":\"Block Insecure Mobile Apps\"},{\"result\":\"failed\",\"subject\":\"Baseline policy: Require MFA for admins\"}]},\"severity\":4}}", "result": "failed", "severity": 4, "subject": "Baseline policy: Require MFA for admins" }
Using Multiple Instances of an Elastic Community Beat with a Custom Pipeline
The following methods are similar, and both are capable of performing unique transformations of logs based on type. Selection of one of these two methods will be up to the end user.
Method 1 uses more complex JQ conditional logic, while method 2 relies on using discrete pipelines to keep the transformation logic separate.
Method 1 - Multiple instances of FileBeat using a single custom pipeline
If you wish to use a single custom JQ pipeline to process logs from all instances of your Elastic Community Beats, you will follow the general design shown here:
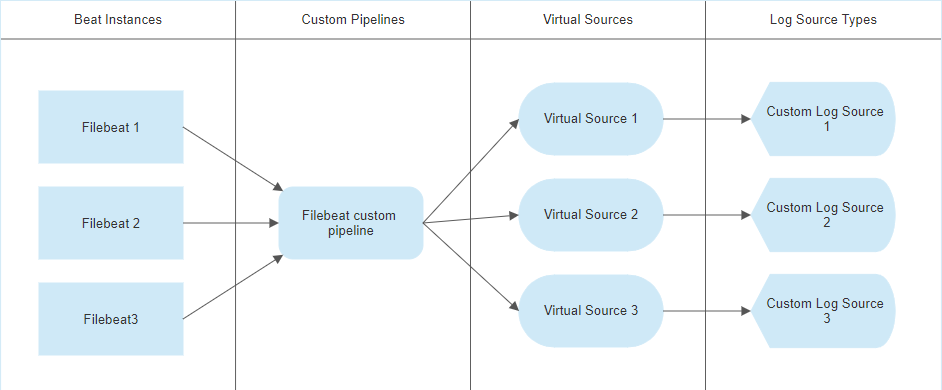
This design relies upon use of conditional logic inside your custom JQ transform to process logs differently based on log content. In our example we are using a pipeline called "customfilebeat".
This design will use a single "is_customfilebeat.jq" file, which matches all logs coming from any FileBeat instance.
Example is_customfilebeat.jq:
# is_customfilebeat checks if the data matches the customfilebeat criteria
def is_customfilebeat:
."@metadata".beat == "filebeat"
;
All logs matching this "is_customfilebeat" file will be directed to a single custom pipeline, shared by all instances of the Elastic Community FileBeat which are currently running.
Logs from each discrete beat may be processed differently by using conditional logic in the "customfilebeat.jq" file. Assume we have access to a field in each log which specifies what type of log it is, e.g. "log_type".
Example customfilebeat.jq (Does not include ancillary functions):
def logtype1_transform:
# Transform logic for log type 1 goes here
;
def logtype2_transform:
# Transform logic for log type 2 goes here
;
# transform will normalize the incoming log into the LogRhythm Schema
# that can then be forwarded to the SIEM
def transform:
# First, convert to IO format.
get_io_format |
# for elastic beats, capture the beatname into our output
add_field(.input."@metadata".beat; .output.beatname) |
# TODO: insert transformation logic here to build output
.input.log_type? as $logtype
if
$logtype == "type1"
then
.output.device_type = "type1" | logtype1_transform
elif
$logtype == "type2"
then
.output.device_type = "type2" | logtype2_transform
else
# Default transform logic goes here or in separate function
end
# this filter produces the output object, for sending to SYSLOG output
# This filter should be left in place in most cases
| .output
;
Additional transformation function declarations must occur above where they are called, or you will receive an error like "failed to parse function logic: error creating conditional output: logtype1_transform/0 is not defined"
With our conditional logic writing different output to the "device_type" key, we may now differentiate the logs downstream using Virtual Sources. Your virtual source(s) will use a regex which looks for an expected type.
Example:
Custom virtual source 1:
beatname="filebeat"\|device_type="type1"
Custom virtual source 2:
beatname="filebeat"\|device_type="type2"
These custom virtual sources may now route to unique custom log source types in the LogRhythm SIEM. Use of the universal regex present in all Open Collector system log source types is recommended.
This method may be expanded to cover as many unique log types or FileBeat instances as are required, by expanding the if/else conditional block and using additional virtual sources and custom log source types.
Method 2 - Multiple instances of FileBeat using multiple custom pipelines
If you wish to use multiple custom JQ pipelines to process logs from your Elastic Community Beats, you will follow the general design shown here:
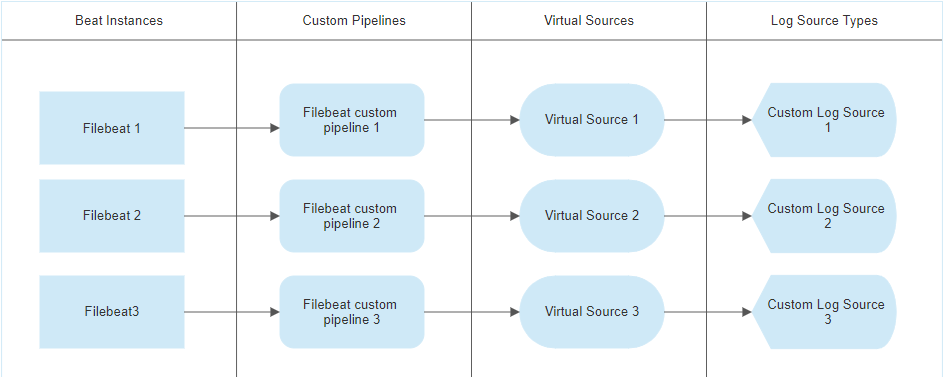
This method relies on using data from the log other than the beatname to determine if a log should hit that pipeline.
-
Example is_filebeat1.jq for FileBeat custom pipeline 1, where a known value of '1' exists in the "identifier" key:
# is_filebeat1 checks if the data matches the filebeat1 criteria def is_filebeat1: ."@metadata".beat == "filebeat" and .identifier == "1" ;
-
Example is_filebeat2.jq for FileBeat custom pipeline 2, where a known value of '2' exists in the "identifier" key:
# is_filebeat2 checks if the data matches the filebeat2 criteria def is_filebeat2: ."@metadata".beat == "filebeat" and .identifier == "2" ;
With your transformation logic for each different pipeline writing unique output to the "device_type" key, we may now differentiate the logs downstream using Virtual Sources. Your virtual source(s) will use a regex which looks for an expected type.
Example:
Custom virtual source 1:
beatname="filebeat"\|device_type="type1"
Custom virtual source 2:
beatname="filebeat"\|device_type="type2"
These custom virtual sources may now route to unique custom log source types in the LogRhythm SIEM. Use of the universal regex present in all Open Collector system log source types is recommended.
This method may be expanded to cover as many unique log types or FileBeat instances as are required, by adding additional pipelines.